调用Malloc后发生了什么
malloc函数是用来进行内存分配的函数, 会在在堆上分配一段内存并返回地址
malloc是glibc函数, 实际上对应的系统调用是brk()函数
进程的地址空间:
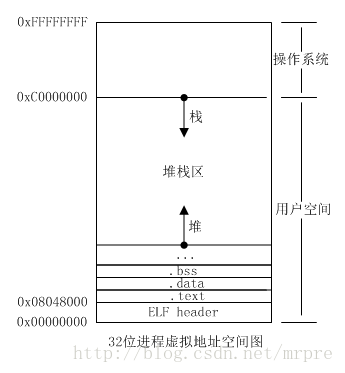
众所周知, 栈由高地址向低地址增加, 堆则从低地址向高地址增加
brk & sbrk
看一下brk和sbrk的用法:
brk和sbrk提供底层的内存分配
共同维护一个系统指针, 用于对同类型的大块数据的动态存放
定义:
int brk(void *end_data_segment); // 通过移动指针分配空间,释放空间
void* sbrk(ptrdiff_t increment); // 分配内存空间,返回指定大小空间的地址
brk用法:
对参数中end_data_segment做[绝对位置]调整,调动指针左右移动,左移-释放空间,右移-分配空间
如果内存分配失败,二者都返回-1
简而言之, brk可以指定堆的结束地址
如当前堆结束地址是0x1000, 调用brk(0x2000), 那么堆结束地址就变成了0x2000, 堆块增加了0x1000的大小
sbrk用法:
第一次调用时,系统分配一大块空闲地址,把首地址返回,分配给一个指针phead,作为首地址不动;
下一次调用时,返回当前位置的地址,分配给一个指针pnow,并把指针指向+increment的地方;
sbrk的参数是一个相对地址, 即当前堆结束地址 + 参数, 并返回
因此可以通过调用sbrk(0)的方式来获取当前堆结束地址
例子:
|
输出:
current brk end:0x98e000
current brk end:0x98f000
程序流程: 获取堆结束地址(sbrk(0)) -> 拓展堆地址0x1000字节(brk(0x1000)) -> 获取堆结束地址(sbrk(0))
显然只用sbrk也可以实现如上程序, 即用sbrk(0x1000)替换brk(p + 0x1000)
如果是使用brk(0x1000)呢?
$ gcc -o test1 test1.c
test1.c: In function ‘main’:
test1.c:8:15: warning: initialization makes pointer from integer without a cast
void *c = 0x1000;
^
$ ./test1
current brk end:0x1e5d000
current brk end:0x1e7e000
why?地址不应该是改到0x001000了吗?
0x0000000000400605 in main ()
gdb-peda$
current brk end:0x623000
gdb-peda$ x/10gx 0x602000
0x602000: 0x0000000000000000 0x0000000000000411
0x602010: 0x20746e6572727563 0x3a646e65206b7262
0x602020: 0x3030303332367830 0x000000000000000a
0x602030: 0x0000000000000000 0x0000000000000000
0x602040: 0x0000000000000000 0x0000000000000000
gdb-peda$ x/10gx 0x623000
0x623000: Cannot access memory at address 0x623000
gdb-peda$ vmmap heap
Start End Perm Name
0x00602000 0x00623000 rw-p [heap]
可以看到调用brk(0x1000)后, 堆末地址会移动到一个不可读的地方, 即0x623000
距离堆顶为0x623000 - 0x602000 = 0x21000, 0x21000 / 0x400 = 132KB
arena
这132KB的空间叫做arena, 由于是主线程分配的, 所以叫main_arena
而其他子线程分配的空间则叫做thread_arena
arena的数量是和处理器的核心数相关的:
32位系统下:
arena数 = 2 * 核心数 + 1.
64位系统下:
arena数 = 8 * 核心数 + 1.
分配arena的策略是:
1. 主线程malloc的时候, 无条件直接分配main arena
2. 分线程分别分配thread arena
3. 当线程数多于arena数时, 循环遍历所有arena, 尝试通过互斥锁锁定第一个可被锁定的arena, 然后给这个多的线程使用
4. 如果没有可用的arena时, 则此线程将被阻塞
数据结构
ptmalloc通过arena, heap, chunk三种层级的数据结构来对内存管理
分别对应heap_info, malloc_state, malloc_chunk三种数据结构
每个线程对应一个arena, 而每个arena包含了多个heap, 每个heap又拥有多个chunk
- heap_info
即heap header, 由于一个arena包括多个heap, 所以给每个heap设置一个header便于管理
typedef struct _heap_info |
- malloc_state
即arena header, 每个线程只有一个arena header, 包括各种bins的信息, top chunk和remainder chunk等信息
struct malloc_state |
- malloc_chunk
即chunk header, 一个heap被分为多个chunk
struct malloc_chunk { |
未被分配时:
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`head:' | Size of chunk, in bytes |P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Forward pointer to previous chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Back pointer to next chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Unused space (may be 0 bytes long) .
. .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`foot:' | Size of chunk, in bytes |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
被分配时:
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |A|M|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User data starts here... .
. .
. (malloc_usable_size() bytes) .
next . |
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| (size of chunk, but used for application data) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|1|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
bins和chunk:
bins直译过来是箱子的意思, 因而bins是和内存回收相关的一个结构
用户释放之前申请的内存时, 操作系统根据释放的内存大小来决定将释放的内存放入哪个bin中
所以bin相当于一个内存回收的分类
而chunk翻译是块, 即数据块, 是内存分配的单位
操作系统根据申请内存大小的不同, 从相应的bin中取出内存来分配
如果没有合适大小的内存会从top chunk中分割一部分内存来分配
剩余内存则放在remainder chunk中
四种类型的bin:
fastbin
fastbin存放最小的chunk, 分配起来也是最快的, 可以分配从0到80byte的chunk
有10个链表, 分别对应不同大小的fastbin(初始化的时候只到64byte而不是80byte, 便于对齐)
fastbin是一个单链表, 操作更快
如果有两个相邻的空闲fastbin是不会合并的, 因而fastbin会在malloc_state结构中独立于其他的bin
大小必须是 2 * SIZE_SZ 的整数倍。
如果申请的内存大小不是 2 * SIZE_SZ 的整数倍,
会被转换满足大小的最小的 2 * SIZE_SZ 的倍数。32 位系统中,SIZE_SZ 是 4;64 位系统中,SIZE_SZ 是 8。
32位下:
| Fastbin | chunk大小 | 实际chunk大小(包括元数据) |
|---|---|---|
| 0 | 00 - 12 | 16 |
| 1 | 13 - 20 | 24 |
| 2 | 21 - 28 | 32 |
| 3 | 29 - 36 | 40 |
| 4 | 37 - 44 | 48 |
| 5 | 45 - 52 | 56 |
| 6 | 53 - 60 | 64 |
| 7 | 61 - 68 | 72 |
| 8 | 69 - 76 | 80 |
| 9 | 77 - 80 | 88 |
64位下:
| Fastbin | chunk大小 | 实际chunk大小(包括元数据) |
|---|---|---|
| 0 | 00 - 24 | 32 |
| 1 | 25 - 40 | 48 |
| 2 | 41 - 56 | 64 |
| 3 | 57 - 72 | 80 |
| 4 | 73 - 88 | 96 |
| 5 | 89 - 104 | 112 |
| 6 | 105 - 120 | 128 |
| 7 | 121 - 136 | 144 |
small bin
small bin 用来存放512byte以内的chunk, 共62个, 每个的间距是8byte
如果有两个相邻的空闲small bin, 则这两个bin会合并
large bin
包含大于512 byte的chunk, 共63个, 间距为8byte
组织方法如下:
32个bin, 每64个byte一个阶层, 第一个512~568(512 + 64 - 8), 第二个576~632...
16个bin, 每512个byte一个阶层
8个bin, 每4096个byte一个阶层
4个bin, 每32768个byte一个阶层
2个bin, 每262144个byte一个阶层
最后一个bin包括剩下的所有大小
和small bin不同的地方在于,这里的每一个bin都保存的是一个范围而不是一个确定的值,每一个bin内的chunk大小是排好序的。不过和small bin一样也可以合并。
unsorted bin
当small bin和large bin中的chunk被释放的时候会放入unsorted bin
只有一个, 是一个循环链表
top chunk和remainder chunk
引用一张图片:
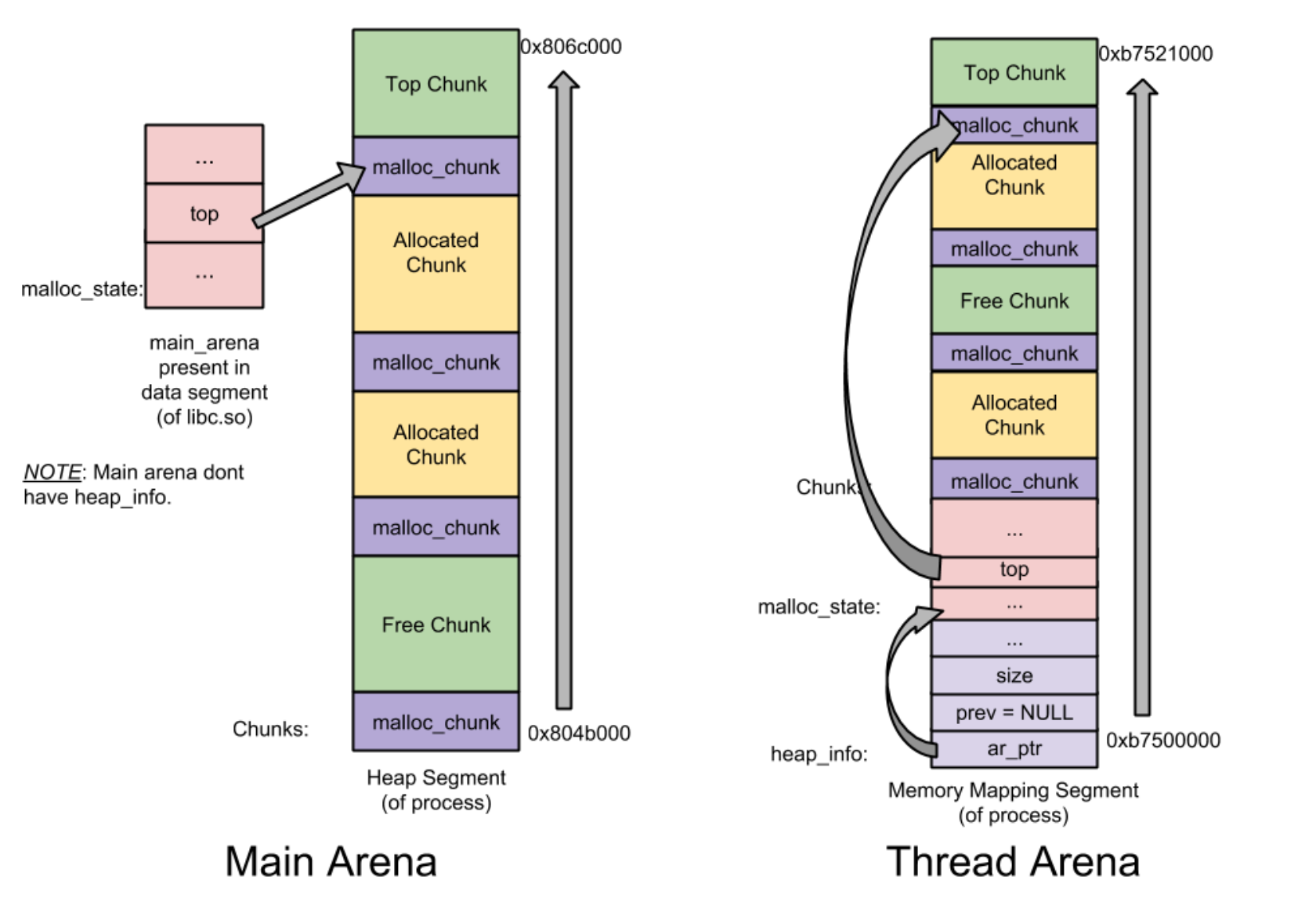
可以看到top chunk是在最上面的(最高地址处), 是一个内存分配的边界(有效内存)
这个chunk不属于任何bin, 默认这个chunk永远存在, 大小不够的时候会通过系统调用来分配新的内存
在main arena通过sbrk分配的内存会直接加入到top chunk来拓展heap
在thread arena通过mmap分配的内存则会拥有新的heap, 同时拥有了新的top chunk
top chunk分配后, 剩下的chunk会分配给remainder chunk
内存操作过程
heap初始化
是在第一次请求分配内存的时候进行的,比如第一次进行malloc的时候。
进行了一系列函数调用,并且设置了初始化标志位,将main_arena的next arena指向自己等等。
在这个阶段,heap还没有被分配。
heap 创建
是在请求分配,初始化完成之后,但是还没有可以进行分配的内存的时候,也就是上述初始化结束之后进行。
跳过一些列函数调用,大概内容也是进行一些数据结构的初始化,不过在这个阶段,在所有bin中依然没有任何可以分配的chunk。
分配fastbin chunk
刚初始化之后max size和索引值均为空,由small bin处理
不为空的时候,计算索引,根据索引找到相应的bin
取走该bin的第一个chunk,第二个chunk成为第一个chunk
将chunk地址转换为用户的mem地址,返回
分配small bin chunk
刚初始化之后small bin都为空。
Small bin某一个bin为空的时候就交给unsorted bin处理
不为空的时候,最后一个chunk被取走
转换为mem地址,返回
分配 large chunk
刚初始化之后,large bin都为空,为空或者large bin中最大的也无法满足要求,就交给下一个最大的bin来处理
不为空的时候,如果最大的chunk大小比请求的空间大,从后往前找能够满足要求的chunk
找到之后,切成两半,一个返回给用户,一个加入unsorted bin
释放
释放基本上就是检查前后一个相邻的chunk是否是空闲的,是空闲的则合并,然后加入unsorted bin,否则直接加入unsorted bin
参考文章:
https://blog.csdn.net/qq_29343201/article/details/59614863
https://www.anquanke.com/post/id/163971